
| 僌儖乕僾暿嵟戝憹暘抣偺専摙 奺僌儖乕僾枅偺嵟戝憹暘抣乮俆暘娫偁偨傝偺嵟戝僂僅僢僠悢乯偼偦偺僌儖乕僾偺儝僞偺摿惈傕偁傝斾妑偡傞偙偲偼擄偟偄丅僌儖乕僾偵傛偭偰偼偄傢備傞敔悇偟偲屇偽傟傞僌儖乕僾偺偳偺儊儞僶乕偱傕墳墖偡傞偲偄偆僼傽儞憌偑懡偄偲偙傠傕偁傟偽丄屄乆偺屄恖傪墳墖偡傞僼傽儞偑婎杮偲側偭偰偄傞僌儖乕僾傕偁傞丅偟偐偟側偑傜婎杮揑偵偼偦偺僌儖乕僾傪墳墖偡傞僼傽儞偵傛偭偰僂僅僢僠妶摦偼巟偊傜傟偰偄偨傢偗偩偐傜丄暋悢偺儊儞僶乕偑僂僅僢僠僶僩儖偵嶲壛偟偰偄偨偺偱偁傟偽丄偦偺奺儊儞僶乕偺摨擔丄摨帪娫偵敪惗偟偨僂僅僢僠悢崌寁偺嵟戝抣偑偦偺僌儖乕僾偺帩偭偰偄傞億僥儞僔儍儖偲峫偊傜傟傞丅 |
|
| 専摙曽朄 専摙曽朄偲偟偰偼偦傟偧傟偺僌儖乕僾偺嵟戝抣偑敪惗偟偨偲帪娫懷傪嵟廔擔偺21:00乣24:00偲梊應偡傞丅偟偐偟側偑傜丄偙偺帪娫偵敪惗偡傞嵟戝抣偼嵟廔擔偺廔椆娫嵺偵敪惗偡傞偲偄偆嬌抁帪娫偵婲偒傞働乕僗偑憐掕偝傟傞丅偦傟偵斾妑偡傞偲忋惣偼廔椆慜1帪娫掱搙摨偠偖傜偄偺抣偱悇堏偟偰偍傝丄偦偺帪娫懷偵嵟戝抣偑敪惗偟偰偄傞丅偟偨偑偭偰忋惣偺僨乕僞偲偟偰斾妑懳徾偲側傞嵟戝抣偼丄彮側偔偲傕1帪娫掱搙偼宲懕偱偒傞傕偺偱側偗傟偽側傜側偄丅偙傟傜偺揰偐傜峫偊傞偲丄嵟戝僨乕僞偲偟偰峫偊傞偙偲偑偱偒傞傕偺偼丄嵟廔擔偺廔椆娫嵺偵偺傒敪惗偡傞傛偆側摿堎側僨乕僞傪彍偄偨丄惓婯暘晍偟偰偄傞偲峫偊傜傟傞僨乕僞曣廤抍偺拞偐傜丄宲懕揑側敪惗偺壜擻惈偑憐掕偱偒傞抣偺拞偱偺嵟戝抣傪慖戰偡傞昁梫偑偁傞丅 偦偙偱僨乕僞偺専摙斖埻偼偦傟偧傟偺僌儖乕僾偺懳徾擔偺19丗35乣24:00偲21:00乣24:00偺2偮偺斖埻偱専摙偟丄偦傟偧傟偺暯嬒乮兪1丆兪2乯偲昗弨曃嵎乮冃1丄冃2乯傪媮傔傞丅偙偙偱壖偵梊憐嵟戝抣乮M)傪兪2亄冃2亊2偲偟偰寁嶼偟偰偍偔丅偦偟偰偦傟偧傟偺嬫娫偺惓婯惈傪専摙偟丄惓婯惈偑擣傔傜傟側偄応崌偵偼丄嬌抂偵崅偄抣傗嬌抂偵掅偄抣側偳惓婯惈偐傜堩扙偡傞傛偆側僨乕僞傪彍偄偰丄偳偺斖埻偺僨乕僞偱嶼掕偡傟偽惓婯惈偑擣傔傜傟傞斖埻偲側傞偐専摙偡傞丅嵟掅尷偺僨乕僞傪彍奜偟偰惓婯惈偑擣傔傜傟傞斖埻傪嶼掕偟偨屻偵丄奺懳徾帪娫懷偺暯嬒乮兪3丆兪4乯偲昗弨曃嵎乮冃3丄冃4乯傪嵞搙媮傔丄兪3亄冃3亊2丄兪4亄冃4亊2傪寁嶼偟丄崅偄抣偵側傞曽偺僌儖乕僾傪嵟戝抣偑敪惗偡傞曣廤抍偲尒側偟丄偦偺曣廤抍偱偺椵愊暘晍娭悢偐傜1亾桳堄悈弨乮婋尟棪1亾乯偱敪惗壜擻偲側傞抣傪嵟戝抣偲偡傞丅傕偟嵟弶偵寁嶼偟偨梊憐嵟戝抣丗M傪1亾桳堄悈弨偱専掕偟偰偦偺曣廤抍偱偺敪惗偑斲掕偝傟側偄応崌偼M傪嵟戝抣偲偡傞偑丄偦偆偱側偄応崌偼椵愊暘晍娭悢偱敪惗妋棪偑99亾偲側傞椵愊暘晍娭悢偺媡娭悢偱媮傔傜傟傞梫慺丗x偲側傞抣傪嵟戝抣偲峫偊傞丅側偍丄僨乕僞梫慺偺惓婯惈偺専掕偵偼僔價儖儚乕僋僗幮採嫙偺僼儕乕僜僼僩偱偁傞惓婯惈専掕僣乕儖傪棙梡偟丄桳堄悈弨1亾偺D'Agostino and Pearson専掕乮K2専掕乯偱専掕偟偨丅 摑寁揑側梡岅偵偮偄偰撻愼傒偵側偄曽岦偗偵丄埲壓偵忋婰偺専掕曽朄傪嵦梡偟偨棟桼媦傃丄梡岅偺奣棯偵偮偄偰愢柧偟偰偍偔丅 |
 |
|
||||||||||||||||||||||||||||||||||||||||||
| 惓婯暘晍偵偮偄偰 忋偺僌儔僼偼Excel2013偺NORM.DIST娭悢傪梡偄偰暯嬒乮兪乯丗0丄昗弨曃嵎乮冃乯丗1偺昗弨惓婯暘晍偲側傞妋棪枾搙娭悢傪媮傔僌儔僼壔偟偨傕偺偱偁傞丅婎杮揑偵惓婯暘晍偺僌儔僼偼暯嬒傪拞怱偲偟丄忋偺傛偆側嵍塃懳徧偺僌儔僼偵側傞丅堦斒揑側僨乕僞偺應掕寢壥傪僌儔僼壔偟偨応崌丄昁偢偟傕偙偺傛偆側偒傟偄偵嵍塃懳徧偺惓婯暘晍偺宍偵僨乕僞偑暘晍偡傞偲偼尷傜側偄丅偦偺堊丄應掕偝傟偨僨乕僞偑惓婯暘晍偲偟偰峫偊傜傟傞僨乕僞偐偳偆偐傪壗傜偐偺曽朄偱専掕偡傞昁梫偑偁傞丅崱夞偼忋偱弎傋偨傛偆偵僼儕乕僜僼僩偱偁傞僔價儖儚乕僋僗幮偺惓婯惈専掕僣乕儖傪梡偄丄寁應偝傟偨憹暘抣僨乕僞偵惓婯惈偑偁傞偐偳偆偐傪妋擣偡傞偙偲偲偟偨丅 |
|||||||||||||||||||||||||||||||||||||||||||
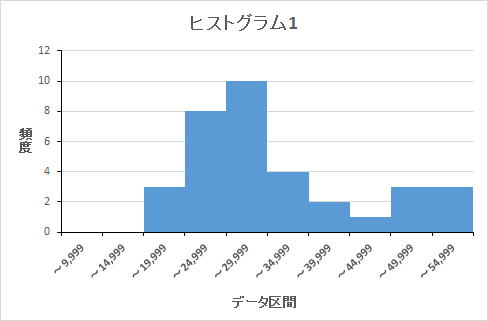 |
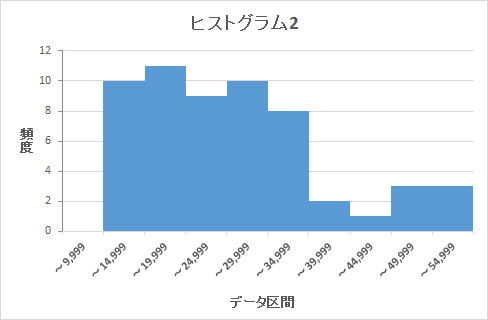
僸僗僩僌儔儉偺嶌惉 堦斒揑偵應掕偝傟偨僨乕僞偑惓婯暘晍傪偟偰偄傞偐偳偆偐傪敾抐偡傞偵偼丄僸僗僩僌儔儉傪嶌偭偰専摙偡傞偙偲偑懡偄丅僸僗僩僌儔儉偼僨乕僞傪嬫娫暘偗偟偰丄偦偺嬫娫枅偵偳傟偩偗偺僨乕僞偑敪惗偟偰偄傞偐傪専摙偡傞偨傔偺曽朄偱偁傞丅堦斒揑偵惓婯暘晍偑梊憐偝傟傞僨乕僞偱偼丄嵍婰偺僸僗僩僌儔儉1偺傛偆偵拞怱晹暘偺昿搙偑崅偔丄嵍塃偵棧傟傞偵偮傟偰昿搙偑掅偔側傞働乕僗偑峫偊傜傟傞丅 偟偐偟丄昁偢偟傕偦偺傛偆側宍偵側傞僨乕僞偽偐傝偱偼側偄丅僸僗僩僌儔儉2偺傛偆側僨乕僞暘晍偲側偭偨応崌丄惓婯暘晍偱偼側偄偲尵偄愗傟傞偐偳偆偐偼敾抐偑擄偟偄丅偦偺堊偵惓婯暘晍偐偳偆偐傪敾抐偡傞僣乕儖偲偟偰丄忋婰偵婰嵹偟偨惓婯惈専掕僣乕儖傪棙梡偟偨丅忋婰専掕僣乕儖偼幚嵺偵應掕偟偨僨乕僞傪梡偄偰偦偺惓婯惈偺敾掕偑偱偒傞傕偺偱偁傞丅 幚嵺偵嵍婰偺僸僗僩僌儔儉2偺尦僨乕僞傪桳堄悈弨5亾偺K2専掕偱敾抐偡傞偲乽惓婯暘晍偱偼側偄乿偲偺敾抐偵側偭偨偑丄僨乕僞嬫娫丗50,000乣54,999偵娷傑傟傞2偮偺僨乕僞偺偆偪丄嵟戝抣偲側傞堦偮彍偔偲乽惓婯暘晍偺壜擻惈偑偁傞乿偲偺敾抐偵側偭偨丅 堦斒揑偵僂僅僢僠僶僩儖偺嵟廔擔偺僨乕僞偱偼丄嵟廔擔偺廔椆娫嵺偵偦偺帪娫懷偩偗嶲壛偡傞恖傗丄嵟屻偺5暘娫偩偗婃挘偭偰僂僅僢僠悢傪忋偘傞偲偄偭偨峴摦傪庢傞恖偑懡偐偭偨丅偦偺偨傔丄宲懕揑偵僂僅僢僠偟懕偗傜傟傞嵟戝抣傪摑寁揑偵媮傔傞偵偼丄偦偆偄偆摿堎側僨乕僞傪彍奜偟偨忋偱丄敪惗偟偆傞嵟戝抣傪専摙偡傞昁梫偑偁傞丅 偟偨偑偭偰丄摑寁揑偵寁嶼偟偰媮傔傞嵟戝抣偲偟偰偼丄惓婯惈専掕僣乕儖偱偦偆偄偭偨摿堎側僨乕僞傪彍奜偟偨忋丄惓婯暘晍偺曣廤抍偲偟偰擣傔傜傟傞斖埻偺僨乕僞傪摿掕偟偰丄偦傟傪梡偄偰専摙偟偨寢壥丄敪惗偟偆傞嵟戝抣傪嶼掕偡傞偙偲偲偟偨丅 偪側傒偵丄嵍婰偺僨乕僞偼5寧3擔偺HKT丗寠堜偺僨乕僞傪尦偵偟偰嶌惉偟偨傕偺偱偁傝丄僸僗僩僌儔儉1偑21:00乣23:50丄僸僗僩僌儔儉2偑19:10乣23:50偺憹暘抣傪僸僗僩僌儔儉偵偟偨傕偺偱偁傞丅 偄偔偮偐偺儊儞僶乕偺僨乕僞傪専掕偟偨偑丄嵟廔擔偱側偄擔偺21:00乣24:00偺娫偺僨乕僞偼丄偳偺儊儞僶乕偺僨乕僞傕桳堄悈弨5亾偺K2専掕偱乽惓婯暘晍偺壜擻惈偑偁傞乿偲偺敾抐偵側傞偙偲偑懡偐偭偨丅 |
||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||
僌儔僼1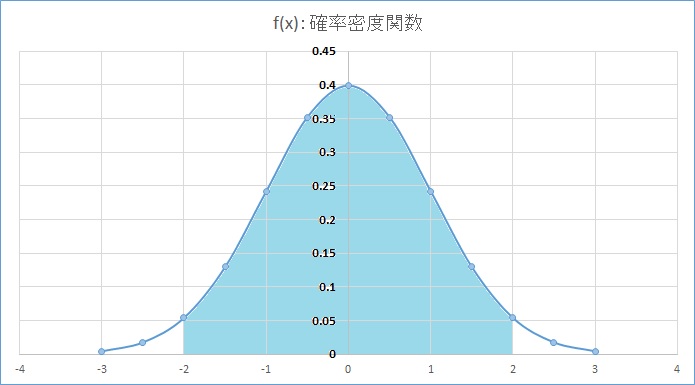 |
椵愊暘晍娭悢 堦斒揑偵惓婯暘晍偟偰偄傞曣廤抍偺僨乕僞偱偼暯嬒乮兪乯丄昗弨曃嵎乮冃乯偵懳偟偰丄兪亇冃偺斖埻偵68.27亾丄兪亇2冃偺斖埻乮僌儔僼1偺悈怓偺晹暘乯偵95.45亾丄兪亇3冃偺斖埻偵99.73亾偺抣偑娷傑傟傞偙偲偑抦傜傟偰偄傞丅傑偨丄堦斒偵椉懁専掕偱棙梡偝傟傞95亾偺抣偑娷傑傟傞乮5亾桳堄悈弨乯偲側傞斖埻偼兪亇1.96冃丄99亾偺抣偑娷傑傟傞乮1亾桳堄悈弨乯偺斖埻偼兪亇2.58冃偲偄偆偙偲偑抦傜傟偰偄傞丅 椵愊暘晍娭悢偼惓婯暘晍偲側傞妋棪枾搙娭悢傪愊暘偟偨傕偺偱偁傝丄尵偄姺偊傟偽偦偺梫慺乮憹暘抣乯丗倶傪嵟戝抣偲偟偰偦偺抣傑偱偵娷傑傟傞梫慺偑丄慡懱偺偳傟偩偗偺妱崌偵側傞偐傪昞傢偟偰偄傞乮僌儔僼2偺悈怓偺晹暘乯丅偦偺堊丄忋偺昞偱偼兪乮0乯傑偱偺椵愊暘晍娭悢偼0.5丄兪亄2冃乮0亄1亊2亖2乯偺椵愊暘晍娭悢偼0.977249868偲側偭偰偄傞偑丄兪傪嵟戝抣偲峫偊傞偲慡懱偺50亾丄兪亄2冃傪嵟戝抣偲偟偰峫偊傞偲偦偺抣傑偱偵慡懱偺97.72亾偺抣偑娷傑傟傞偲偄偆偙偲傪堄枴偡傞丅崱夞偼敪惗偟偆傞嵟戝抣傪媮傔傞偙偲傪栚揑偲偟偰偄傞偺偱丄曅懁専掕偱1亾桳堄悈弨偱専掕偡傞応崌丄椵愊暘晍娭悢偲偟偰99亾偺抣偑娷傑傟傞抣傪媮傔傞偙偲傛偭偰専掕偡傞偙偲偑偱偒傞丅偮傑傝丄椵愊暘晍娭悢偺媡娭悢傪棙梡偟偰暯嬒丄昗弨曃嵎偐傜椵愊暘晍娭悢偑99亾偲側傞梫慺乮憹暘抣乯丗x偺抣傪媮傔傞丅 偦偆傗偭偰梫慺乮憹暘抣乯丗x偺抣傪寁嶼偵傛偭偰媮傔傞偙偲偑偱偒傟偽丄偦偺抣偑1亾桳堄悈弨乮婋尟棪丗1亾乯偱偦偺曣廤抍偵偍偄偰敪惗偟偆傞嵟戝抣偩偲敾抐偡傞偙偲偑偱偒傞丅扐偟丄偙偺寁嶼偐傜媮傔傞抣偼偁偔傑偱傕曣廤抍偑惓婯暘晍偟偰偄傞僨乕僞偱偁傞応崌偵懨摉惈傪帩偮傕偺偱偁傝丄尦偺僨乕僞傪惓婯惈専掕僣乕儖偱専掕偟丄摿堎側僨乕僞傪彍偄偨屻偵奺僨乕僞傪梡偄暯嬒偲昗弨曃嵎傪媮傔傞昁梫偑偁傞丅 壖偵偦傟傛傝戝偒側抣偑敪惗偟偰偄偨偲偟偰傕丄偦傟偼偦偺曣廤抍偐傜帺慠敪惗揑偵婲偒偨帠徾偲偼尵偊偢丄堄恾揑傕偟偔偼恖堊揑偵壗傜偐偺曽朄偱敪惗偝偣偨帠徾偲偄偆偟偐側偄丅傕偟偔偼曣廤抍傪暿偵偟偰敪惗偟偨尰徾偩偲尵偊傞偐傕偟傟側偄丅 崱夞丄椵愊暘晍娭悢偺媡娭悢偲偟偰偼Excel2013偱偺NORM.INV娭悢傪梡偄偰抣傪媮傔傞偙偲偲偟偨丅 |
僌儔僼俀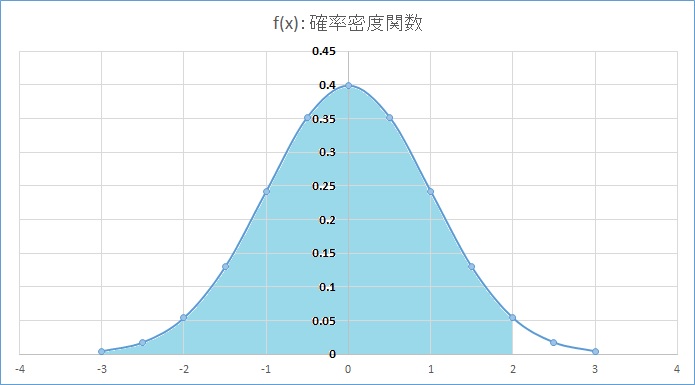 |
|
| 埲忋偺曽朄偱嶼掕偟偨惓婯暘晍僨乕僞偲偟偰峫偊傜傟傞曣廤抍偐傜媮傔偨嵟戝抣丄暯嬒丄昗弨曃嵎傪婎弨偵偟偰丄HKT丄NMB丄SKE奺僌儖乕僾偵偍偗傞嵟戝憹暘抣傪悇應偟丄偦傟傪僌儖乕僾慡懱偑帩偮偺億僥儞僔儍儖偲偟偨丅偦偺奺僌儖乕僾偺寢壥傪梡偄丄5寧3擔偵偍偗傞忋惣偺梊憐僨乕僞偺懨摉惈丄媦傃幚應僨乕僞偺堎忢惈傪専摙偡傞丅 |
|
| HKT:僌儖乕僾嵟戝憹暘抣梊應 | NMB:僌儖乕僾嵟戝憹暘抣梊應 |
| SKE:僌儖乕僾嵟戝憹暘抣梊應 | 寠堜嵟廔擔僨乕僞偺専掕 |
| 忋惣嵟廔擔僨乕僞偺専掕 | |
 僩僢僾傊栠傞 僩僢僾傊栠傞 |